Building a Local Knowledge Worker with LLMs
Catch up
It has been a moment since writing a blog post. I recently built out an iOS app for tracking my weightlifting and running. After programming on the project in my free time for two months, I needed a break. So my attention turned back to using my local machine's gpu to explore the world of large language models (LLMs) and how they can be personalized with our own data privately.
Building a Local Knowledge Worker with LLMs
Before my dive into the iOS app, I was working on fine-tuning a local large language model (LLM) directly on my Linux desktop. My initial focus was on autonomous vehicles—experimenting with how self-driving car models are trained using real-world data.
But eventually, I shifted my attention toward large language models and how we can personalize them with our own data.
Round One: Manual Data Injection (and Failure)
My first attempt at personalizing an LLM involved manually injecting data into the model. I quickly realized this was more complex than expected and, honestly, didn’t get great results. But I wasn’t discouraged—I saw it as a learning opportunity and began planning a more structured second attempt.
Round Two: The Knowledge Worker
This time, I set out to build something I call a Knowledge Worker—a local, command-line-based assistant powered by a language model running entirely on my machine. The idea was simple but powerful: install a local LLM, ingest domain-specific documents (like PDFs), and fine-tune or customize the model to answer questions with high context-awareness.
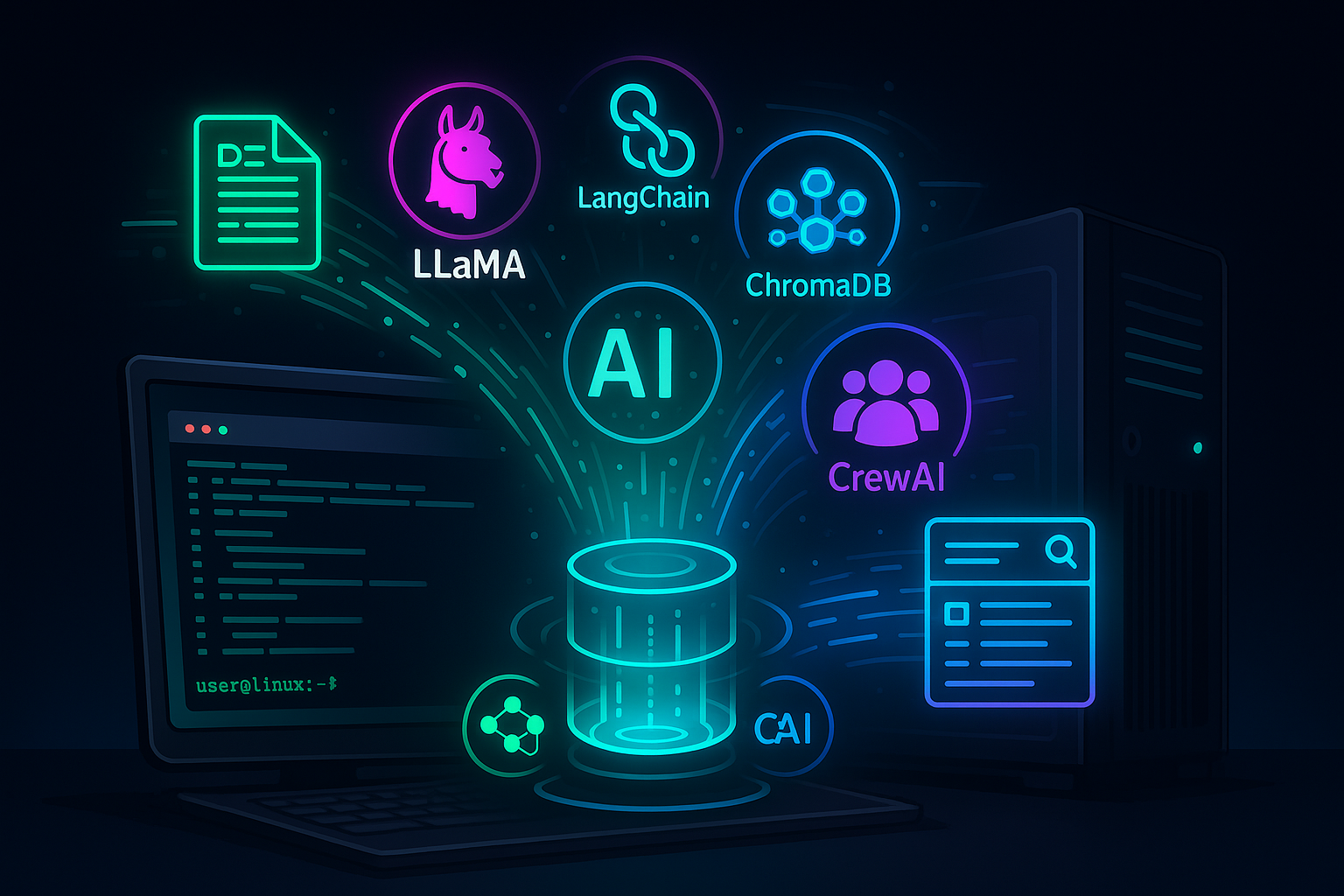
The Stack
Here’s what I used to build it:
Model: LLaMA 2 7B Chat (Q2_K GGUF format), downloaded from Hugging Face
Model Loader: llama-cpp-python to run the model locally via CPU/GPU
Vector DB: ChromaDB for storing and retrieving embeddings
Embedding Models: Sentence Transformers
Tooling: LangChain for orchestration
Document Parsing: unstructured for extracting text from PDFs
Agents & Search: CrewAI and duckduckgo-search to enable real-time web research
The Workflow
Load a Model
I used llama-cpp-python to load my quantized LLaMA 2 model entirely offline.
Ingest Documents
I fed the app a few PDF documents—mostly training guides and exercise science research. Using LangChain and ChromaDB, I parsed and embedded the contents into a vector database.
Question Answering
Once indexed, I could query the system about specific training methodologies. For example, I asked it to summarize a trainer’s workout philosophy, and it returned detailed, contextually accurate answers.
Chaining with Research Agents
To go beyond static document analysis, I added CrewAI agents equipped with DuckDuckGo search. This allowed the assistant to combine internal knowledge (from PDFs) with fresh data from the web in a single response chain.
Why This Matters
Many want the power of AI without relying on external APIs or exposing sensitive data. A locally hosted model that can read internal docs, scan the web, and generate actionable insights could supercharge internal workflows, research, and decision-making—all while preserving privacy.